Data Organization
Learning Objectives
- Gain a general understanding of data organization
- Be able to identify data organization challenges and solutions
Lesson Overview
You have taken on the data analysis role for your project and you are READY and WILLING! Your sequencing facility has let you know your data is ready, and you are dreaming of your Nature publication in the works. What should you be doing as a first step?
"Creativity is a gift, it doesn’t come through if the air is cluttered."
This lesson will be a discussion of data organization using an example of project.
Introduction
Good morning, Mr/Mrs. Scientist. Your mission, should you choose to accept it, will be to organize the initial files in a large sequencing project. Should you or any of your force be caught with messy data, we will disavow any knowledge of your actions. Good luck.
Background:
The Experiment
You have two groups of E. coli (3 E. coli in each group as biolgoical triplicates). These E. coli are grouped as being grown with different different media (Propietary Media #77: a Fritos-extract only diet and Propietary Media #50:a carrots-extract-only diet). You have sampled DNA at intermittent time periods over the course of an eight week study. This DNA has been experimentally separated into three unique size fractions based on previous experimental methods (XL, AVG, and TINY).
The players
Rarely is a man/woman an island in these experiments.
Exercise
Identify who is involved in the data of this sequencing experiment?
Think about the steps of this experiment and which ones generate data, what type, and who is likely to contribute to it? Data comes from not only bioinformatics but also wet-lab techniques.
Data Type 1, DNA extraction and the value of data standards
Imagine that you have come onto this project last week and luckily the data is ready but you have to work with a team that has already influenced your data organization. A past graduate student in your lab had extracted DNA and sent it to The Sequencing Facility. Her name was Diane Rockstar. As she is a rockstar, she had labelled her samples with her initials and a number (in order of how she extracted the DNA).
Here's what her samples looked like when she submitted them to the DNA facility.
Exercise:
Take a couple minutes to look at this data, can you identify some problems with this datasheet?
A note on file formats
What does an excel sheet look like to my computer?
Some data requires a program to read it tractably. Excel is one of these special programs that reads excel worksheets. Here's what the spreadsheet (part of it) you worked withlooks like to your computer without Excel:
�%#����T�)���)�eFa���Bɶ�l6
���,�0�l %kc�w�cՂX8�"�>�ē��/y���=�"
T�T�Ċ�s�kƓ���l �Z���ht�+g#ؘ�N
�M'P����ㆶw$�β�ݹΪd�{�* �wQޛ@�@������
Gross!!!!
Many of you may know that you can save excel into other formats that would not require excel to read them. Go into Excel and save the file as a text format, this includes csv (comma separated values file format) or tsv (which Excel saves as a file name ending in .txt and stands for tab separated values.). To your computer this file will look something like this:
Sample Name Diet Replicate Date of Sample
Fraction DNA Extracted (ug)^MDR1 50 A 12-Feb
XL 50^MDR2 50 B 12-Feb XL 553^MDR03
50 C 12-Feb XL 1003^MDR4 50 A 6-
Mar XL 2000^MDR5 50 B 6-Mar XL
Still, pretty scary looking but better than the first right?
We'll talk about how to deal with these formats going forward but its important to know the difference of the formats and who will be using these files.
For example, will these downstream users (including yourself) be using Excel when they analyze the datasets? In sequencing, the answer is often no!
It is often worth thinking about what standards are important in your analyses prior to sharing data with others.
Data Type II, from the sequencing facility
Your DNA sequencing data is ready and the data onslaught is now ready to begin.
You receive link to an FTP site (one way to transfer data between your computer and the sequencing facilities computing).
The typical sequencing project will have either all your sequencing files in one folder or separate folders for each sample. The data you will get will likely include your sequencing files and run-specific metadata (e.g., lane, date, operator).
Exercise.
Discuss: To keep or not keep Raw data? What are the advantages? Disadvantages?
Here's what the data organization of the sequencing facility looks like:
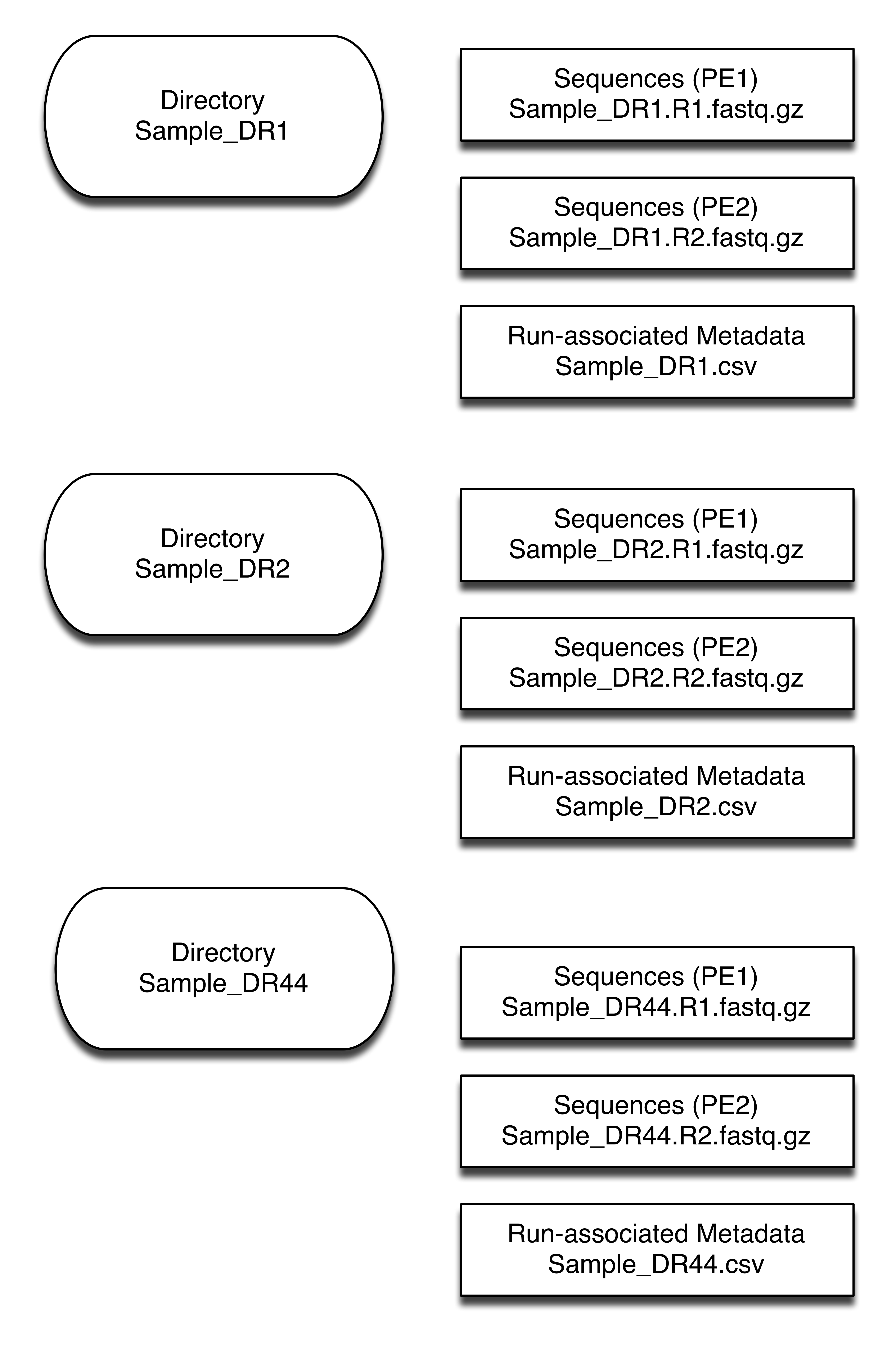
Exercise.
You want to test a hypothesis that each day, fraction, and media will contain genes that are signicantly different under varying treatments. How does the sequencing facility organization and the organization of files for your analysis differ? What about the naming of the files? Are they useful to you? Draw a data organization structure that you would recommend.
Concluding notes
This lesson is a bit challenging as there is no "right" answer that can be universally applied for everyone's data organization. For different questions, you might have data organized in multiple, equally, effective ways.
As we go through the next couple days, you are going to learn ways to automate data access and analysis. Try to think of why standard names and organization structures will impact these activities.